資料內(nèi)容:
1. 監(jiān)督學(xué)習(xí)和非監(jiān)督學(xué)習(xí)簡(jiǎn)介
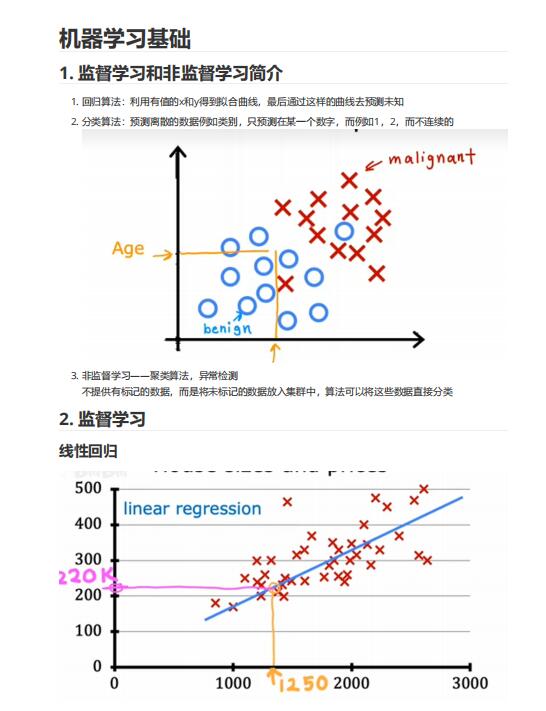
1. 回歸算法:利用有值的x和y得到擬合曲線,最后通過這樣的曲線去預(yù)測(cè)未知
2. 分類算法:預(yù)測(cè)離散的數(shù)據(jù)例如類別,只預(yù)測(cè)在某一個(gè)數(shù)字,而例如1,2,而不連續(xù)的
3. 非監(jiān)督學(xué)習(xí)——聚類算法,異常檢測(cè)
不提供有標(biāo)記的數(shù)據(jù),而是將未標(biāo)記的數(shù)據(jù)放入集群中,算法可以將這些數(shù)據(jù)直接分類
2. 監(jiān)督學(xué)習(xí)
梯度下降
最小化所有函數(shù)的算法,參數(shù)隨便取值
局部最小:對(duì)待不同的路線會(huì)有局部最小值,需要比較局部最小值
學(xué)習(xí)率:控制下降的步幅

